用 AI API 搭建智能客服机器人:完整实战方案
·9 分钟阅读·37 次阅读
智能客服机器人是 AI API 最常见的应用场景之一。本文将从零开始,带你搭建一个支持多轮对话、知识库检索、流式输出的智能客服系统。
为什么用 AI 做客服
传统客服系统面临几个核心痛点:- 人力成本高:7x24 小时值守需要大量人力
- 响应速度慢:高峰期排队等待影响用户体验
- 知识不一致:不同客服回答口径不统一
- 无法规模化:业务增长时客服团队难以同步扩张
系统架构
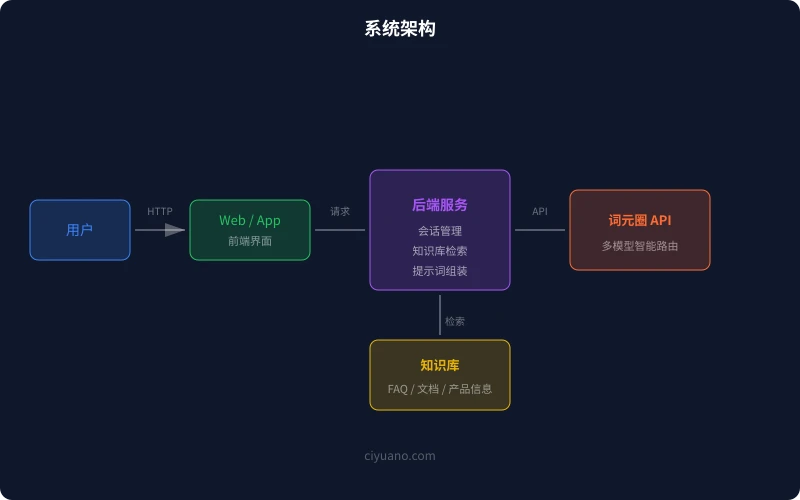
一个完整的 AI 客服系统包含以下组件:
| 组件 | 职责 | 技术选型 |
|---|---|---|
| 前端界面 | 用户对话入口 | React / Vue / 小程序 |
| 后端服务 | 业务逻辑、会话管理 | Node.js / Python / Go |
| 知识库 | FAQ、产品文档 | 向量数据库 / 本地文件 |
| LLM API | 自然语言理解与生成 | 词元圈 API |
基础实现
1. 初始化客户端
from openai import OpenAI
client = OpenAI(
base_url="https://www.ciyuano.com/v1",
api_key="sk-your-api-key"
)2. 定义系统提示词
系统提示词决定了客服的角色、语气和行为边界:
SYSTEM_PROMPT = """你是「词元圈」的智能客服助手。
你的职责:
1. 回答用户关于 API 接入、定价、模型选择的问题
2. 协助排查接入过程中的常见问题
3. 对于无法解决的问题,引导用户联系人工客服
规则:
- 只回答与词元圈产品相关的问题
- 不确定的信息不要编造,告知用户需要确认
- 回答简洁明了,避免冗长
- 使用中文回答"""3. 实现多轮对话
class CustomerServiceBot:
def __init__(self):
self.client = OpenAI(
base_url="https://www.ciyuano.com/v1",
api_key="sk-your-api-key"
)
self.conversations = {} # session_id -> messages
def chat(self, session_id: str, user_message: str) -> str:
# 获取或创建会话
if session_id not in self.conversations:
self.conversations[session_id] = [
{"role": "system", "content": SYSTEM_PROMPT}
]
messages = self.conversations[session_id]
messages.append({"role": "user", "content": user_message})
# 调用 LLM
response = self.client.chat.completions.create(
model="deepseek-v4",
messages=messages,
temperature=0.3,
max_tokens=1000
)
assistant_message = response.choices[0].message.content
messages.append({"role": "assistant", "content": assistant_message})
return assistant_messageRAG 知识库检索
纯靠 LLM 的通用知识无法回答业务 specific 的问题。RAG(检索增强生成)通过先检索相关文档,再让 LLM 基于检索结果生成回答,解决了这个问题。
知识库构建流程
import numpy as np
class KnowledgeBase:
def __init__(self):
self.documents = []
self.embeddings = []
def add_document(self, content: str, metadata: dict):
"""添加文档到知识库"""
embedding = self._get_embedding(content)
self.documents.append({"content": content, "metadata": metadata})
self.embeddings.append(embedding)
def search(self, query: str, top_k: int = 3) -> list:
"""检索最相关的文档"""
query_embedding = self._get_embedding(query)
similarities = [
self._cosine_similarity(query_embedding, emb)
for emb in self.embeddings
]
top_indices = np.argsort(similarities)[-top_k:][::-1]
return [self.documents[i] for i in top_indices]
def _get_embedding(self, text: str) -> list:
"""获取文本向量"""
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
def _cosine_similarity(self, a, b) -> float:
"""计算余弦相似度"""
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))RAG 增强对话
def chat_with_rag(self, session_id: str, user_message: str) -> str:
# 1. 检索相关知识
relevant_docs = self.knowledge_base.search(user_message, top_k=3)
context = "
".join([doc["content"] for doc in relevant_docs])
# 2. 组装带知识的提示词
enhanced_prompt = f"""{SYSTEM_PROMPT}
以下是从知识库中检索到的相关信息,请基于这些信息回答用户问题:
{context}
"""
messages = [
{"role": "system", "content": enhanced_prompt},
{"role": "user", "content": user_message}
]
# 3. 调用 LLM
response = self.client.chat.completions.create(
model="deepseek-v4",
messages=messages,
temperature=0.3
)
return response.choices[0].message.content流式输出
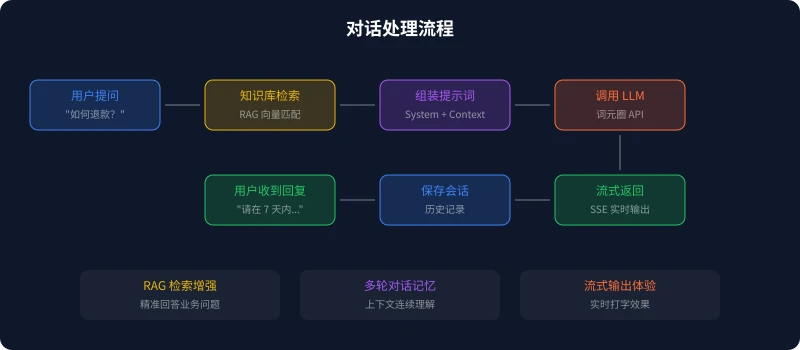
流式输出让用户看到「打字效果」,大幅改善等待体验:
def chat_stream(self, session_id: str, user_message: str):
"""流式返回,逐字输出"""
messages = self._get_messages(session_id, user_message)
stream = self.client.chat.completions.create(
model="deepseek-v4",
messages=messages,
temperature=0.3,
stream=True # 开启流式
)
full_response = ""
for chunk in stream:
if chunk.choices[0].delta.content:
token = chunk.choices[0].delta.content
full_response += token
yield token # 逐字返回给前端
# 保存完整回复到会话历史
messages.append({"role": "assistant", "content": full_response})前端通过 SSE(Server-Sent Events)接收流式数据:
// 前端 JavaScript
async function sendMessage(message) {
const response = await fetch('/api/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ message })
});
const reader = response.body.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
const text = decoder.decode(value);
appendToChat(text); // 逐字显示
}
}模型选择建议
| 场景 | 推荐模型 | 原因 |
|---|---|---|
| 简单 FAQ 问答 | Qwen Plus | 成本低,响应快 |
| 复杂业务咨询 | DeepSeek V4 | 推理能力强,中文好 |
| 需要工具调用 | MiMo v2.5 PRO | Function Calling 支持好 |
| 性价比优先 | MiMo v2.5 | 限时免费 |
优化建议
会话管理
- 设置会话过期时间(建议 30 分钟无活动自动关闭)
- 限制历史消息轮数(建议保留最近 10 轮),避免 token 超限
- 对长对话进行摘要压缩,保留关键信息
提示词优化
- 明确角色边界:告诉模型什么该回答、什么不该回答
- 提供Few-shot 示例:给出标准问答对,统一回答风格
- 设置兜底策略:当模型不确定时,引导用户联系人工
成本控制
- 简单问题用小模型,复杂问题用大模型(路由策略)
- 设置 max_tokens 限制输出长度
- 对重复问题缓存回答
完整示例代码
以下是一个可直接运行的完整示例:
from openai import OpenAI
client = OpenAI(
base_url="https://www.ciyuano.com/v1",
api_key="sk-your-api-key"
)
SYSTEM_PROMPT = """你是智能客服,请简洁、准确地回答用户问题。"""
def chat(user_message: str, history: list = None):
if history is None:
history = []
messages = [{"role": "system", "content": SYSTEM_PROMPT}]
messages.extend(history)
messages.append({"role": "user", "content": user_message})
response = client.chat.completions.create(
model="deepseek-v4",
messages=messages,
temperature=0.3,
stream=True
)
full_response = ""
for chunk in response:
if chunk.choices[0].delta.content:
token = chunk.choices[0].delta.content
full_response += token
print(token, end="", flush=True)
history.append({"role": "user", "content": user_message})
history.append({"role": "assistant", "content": full_response})
return full_response, history
# 交互式对话
if __name__ == "__main__":
history = []
print("智能客服已启动,输入 'quit' 退出
")
while True:
user_input = input("用户: ")
if user_input.lower() == "quit":
break
print("客服: ", end="")
response, history = chat(user_input, history)
print("
")总结
搭建一个 AI 客服系统的核心步骤:
- 选择 API:注册词元圈,获取 API Key
- 设计提示词:定义客服角色、职责、回答规则
- 实现对话:多轮对话管理 + 流式输出
- 接入知识库:RAG 检索增强,回答业务 specific 问题
- 持续优化:根据用户反馈调整提示词和知识库
整个过程只需几十行 Python 代码,配合词元圈的 API 即可完成。对于中小型业务,这套方案足以覆盖 80% 以上的客服场景。
相关文章
评论功能暂未开放,敬请期待